
Because datacenters are very dependent on iSCSI, with an increasing amount of diskless servers booted directly off iSCSI NAS devices, a rock-solid operation of iSCSI is mandatory. The system should not fail even if the connection between iSCSI target and initiator is broken.
IET, or iSCSI Enterprise Target, is an “open source iSCSI target with professional features, that works well in enterprise environment under real workload, and is scalable and versatile enough to meet the challenge of future storage needs and developments”.
By default, Open-iSCSI initiators2 are able to deal only with very brief disconnections. They determine connectivity by sending iSCSI NOP-outs as pings every 10 seconds. If no response is received in 120 seconds, the connection is considered failed, and an error is returned to the SCSI layer. As a result, the SCSI layer offlines the device. We can compare it to a regular server with its hard disk removed during normal operation. In this case the in-memory data is not written to the disk, filesystems are not cleanly unmounted, while the server keeps running in a failing state.
120 seconds is definitely too short. Replacing cabling, failing switch, upgrading a SAN or simply human errors that interrupts the connection for longer than 2 minutes should not bring the datacenter to an unpleasant halt.
After a testing period, I determined that the initiator, when set up properly, can handle disconnections lasting several minutes, hours, or even days. Where previously, failing hardware or operator mistake would cause corrupted filesystems, perhaps damaged data, and a need to restart several servers manually, now, the iSCSI initiator will handle such situations graciously. Processes will just be in an uninterruptible sleep state, waiting for I/O operations to complete. Once the connection is re-established, processes would continue to work correctly.
However, moving that knowledge into production was harder than expected, and extremely hard to debug. Even a short, few-seconds disconnection was causing a lot of trouble – devices offlined immediately, corrupted filesystems, and painful server restarts. Worse – there was no 100% way to reproduce it reliably – tcpdump, running IET daemon process with changed options, on different architectures, or in a debugger did not give any obvious hints. In the end, after a lot of testing, the diagnose was clear: it’s not the initiator’s problem it does not depend on architecture (x86, x86_64, ARM) there need to be hundreds of connected initiators to reproduce it all these hundreds of initiators need to be connected, disconnected (because of the SAN restart, IET daemon process restart, cabling etc.) and then, connected again
Why does this phenomenon occur? We can call it a DDoS on the IET daemon: when hundreds of initiators are disconnected, they try to send a iSCSI NOP-out pings every 10 seconds to the target, and finally, determine that the connection is broken. When the connection is available again, all these hundreds of initiators try to re-establish the connection at the same time. A mathematical approach: with ~200 initiators, and NOP-out pings sent every 10 seconds, on average, it makes ~20 of them try to reconnect every second. It is an unrealistic scenario that everything is distributed evenly. In fact, tcpdump tests show 50-100 initiators trying to reconnect to the target at almost the same time.
The following patch solved the problem:
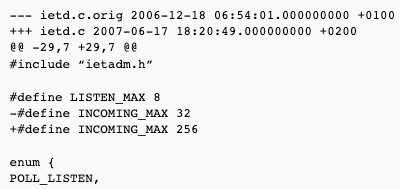
In ietd.c, the size of incoming[] array is decided by hardcoded, compile-time INCOMING_MAX. This is the maximum number of incoming connections ietd can process in a login session. When the iSCSI connection is fully established and reaches its full feature phase, it is passed to the kernel and this resource is available again. So it is only needed to increase this number for “connection storm” cases, when suddenly every initiator tries to connect.
Lesson learnt: always abuse your test system in every way you can imagine.